评论系统功能和架构设计
评论系统功能和架构设计
转载自stormspirit,原文链接:评论系统功能和架构设计
本周会以 B 站的评论系统为样本,来介绍该系统的功能、架构、存储、可用性设计等。
首先在设计一个评论系统之前,我们必须要对这个系统的功能以及定位有一个清晰的了解。
功能模块
架构设计最重要的就是 「理解整个产品体系在系统中的定位。搞清楚系统背后的背景,才能做出最佳的设计和抽象。不要做需求的翻译机,先理解业务背后的本质,事情的初衷。」 深入到业务里面,了解业务本身的本质。成为某个业务领域的专家,对这个业务的系统有比较深的理解,才能设计出一个全面的架构。
评论系统,我们往小里做就是视频评论系统,往大了做就是评论平台,可以接入各种业务形态,比如在漫画、文章等业务下也能接入一样的评论系统。再往大做可以是一个评论中台,只需要设置不同的评论策略,比方说先审后发或者先发后审,或者高于多少等级的用户才能发表评论,这样不同的业务只需要设计自己的策略接入评论系统即可。
评论系统可能有的功能:
- 发布评论: 支持回复楼层、楼中楼。
- 读取评论: 按照时间、热度排序。
- 删除评论: 用户删除、作者删除。
- 管理评论: 作者置顶、后台运营管理(搜索、删除、审核等)。
在前期花足够时间去反复思考设计,会减少之后大量的返工。「在动手设计前,反复思考,真正编码的时间只有5%。」
架构设计
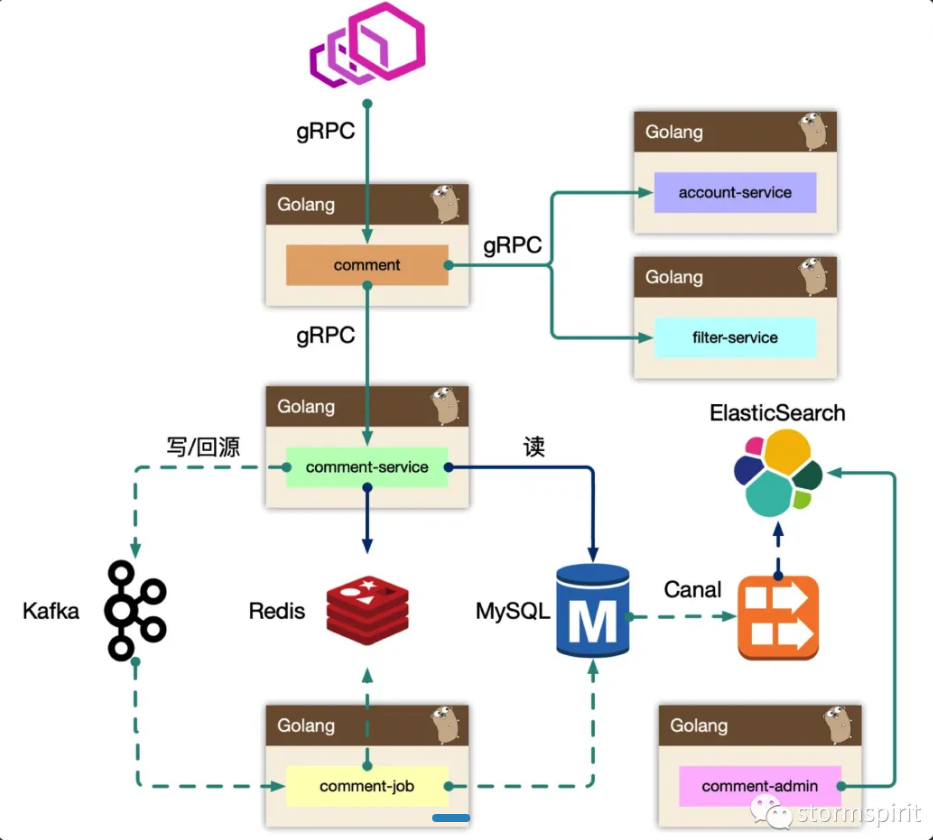
如上图,一共有以下模块:
网关层:api gateway,可能是 nginx 、kong 等。
BFF 层:comment 模块。
复杂评论业务的服务编排,比如访问账号服务进行等级判定,同时需要在 BFF 面向移动端/WEB场景来设计 API,「这一层抽象把评论的本身的内容列表处理(加载、分页、排序等)进行了隔离,关注在业务平台化逻辑上」。
服务层:comment-service。
服务层,去平台业务的逻辑,专注在评论功能的 API 实现上,比如发布、读取、删除等,「关注在稳定性、可用性上,这样让上游可以灵活组织逻辑,从而把基础能力和业务能力剥离」。
Job:comment-job。
消息队列的最大用途是**「削峰处理」**。
Admin: comment-admin。
管理平台,「按照安全等级划分服务」,尤其划分运营平台,他们会共享服务层的存储层(MySQL、Redis)。运营体系的数据大量都是检索,我们使用 canal 订阅 MySQL 的 binlog 进行同步到 ES 中,整个数据的展示都是通过 ES,再通过业务主键更新业务数据层,这样运营端的查询压力就下方给了独立的 fulltext search 系统。
Dependency: account-service、filter-service。
整个评论服务还会依赖一些外部 gRPC 服务,统一的平台业务逻辑在 comment BFF 层收敛,这里 account-service 主要是账号服务,filter-service 是敏感词过滤服务。
架构设计等同于数据设计,梳理清楚数据的走向和逻辑。尽量避免**「环形依赖」**、数据双向请求等(比如两个服务互相调用)。
comment-service
comment-service,专注在评论数据处理(Separation of Concerns)。
注意
我们一开始是 comment-service 和 comment 是一层,业务耦合和功能耦合在一起,非常不利于迭代,当然在设计层面可以考虑目录结构进行拆分,但是架构层次来说,迭代隔离也是好的。
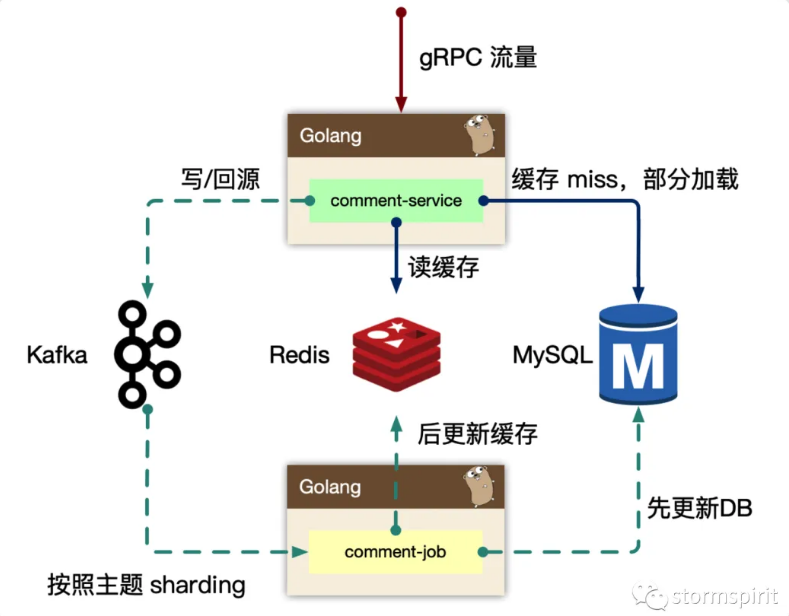
读的核心逻辑
Cache-Aside 模式,先读取缓存,再读取存储。
早期 cache rebuild 是做到服务里的,对于重建逻辑,一般会使用 read ahead 的思路,即 「预读」,用户访问了第一页,很有可能访问第二页,所以缓存会超前加载,避免频繁 cache miss。当缓存抖动时候,特别容易引起集群 thundering herd 现象(惊群问题)。大量的请求会在 「comment 服务内部」 触发 cache rebuild,容易导致服务 OOM。
所以在回源的逻辑里,我们使用了消息队列来进行逻辑异步化。发生缓存 miss 时,服务去 db 把数据拿出来返回,然后发送一条消息给 kafka,说明哪个 topic 或者 key cache miss 了,之后再在 comment-job 里消费消息,从 db 里拿出对应的数据再更新到缓存里。
写的核心逻辑
写可以认为是 「透穿到存储层」 的,系统的瓶颈往往就来自于存储层,或者有状态层。
对于写的设计上,把对存储的直接冲击 「下放到消息队列」,按照消息反压的思路,即如果存储 mysql 延迟升高,消费能力就下降,然后消息堆积,系统始终以最大化方式消费。意思就是把消息都暂存在 kafka 中,而不会一下发到 mysql ,这就是做一个削峰的处理。
Kafka 是存在 partition 概念的,可以认为是物理上的一个小队列,一个 topic 是由一组 partition 组成的,所以 Kafka 的吞吐模型理解为: 「全局并行,局部串行的生产消费方式」。对于入队的消息,可以按照 hash(comment_subject) % N(partitions) 的方式进行分发。即某个评论主题的数据都在一个分区里,这样方便我们串行消费,顺序不会乱。
处理之前的回源消息也是类似的思路。
comment-admin
mysql binlog 中的数据被 canal 中间件流式消费,获取到业务的原始 CRUD 操作,需要回放录入到 es 中,但是 es 中的数据最终是面向运营体系提供服务能力,需要检索的数据维度比较多,在入 es 前需要做一个异构的 joiner,把单表变宽预处理好 join 逻辑,然后导入到 es 中。 一般来说,运营后台的检索条件都是组合的,使用 es 的好处是 「避免依赖 mysql 来做多条件组合检索」(索引越多写入速度会越慢),同时 mysql 毕竟是 OLTP 面向线上联机事务处理的。通过冗余数据的方式,使用其他引擎来实现。
es 一般会存储检索、展示、primary key 等数据,当我们操作编辑的时候,找到记录的 primary key,最后交由 comment-admin 进行运营测的 CRUD 操作。
内部运营体系基本都是基于 es 来完成的。
BFF-comment
comment 作为 BFF,是面向端,面向平台,面向业务组合的服务。所以平台扩展的能力,我们都在 comment 服务来实现,方便统一和准入平台,以统一的接口形式提供平台化的能力。
- 依赖其他 gRPC 服务,整合统一平台测的逻辑(比如发布评论用户等级限定)。
- 直接向端上提供接口,提供数据的读写接口,甚至可以整合端上,提供统一的端上 SDK。
- 需要对非核心依赖的 gRPC 服务进行降级,当这些服务不稳定时。