MySQL 基础知识
MySQL 基础知识
1. 基础
1.1 连接
MySQL服务器启动完毕后,然后再使用如下指令,来连接 MySQL 服务器:
mysql -u用户名 -p密码 [-h数据库服务器的IP地址 -P端口号]命令解释
-h 参数不加,默认连接的是本地 127.0.0.1 的 MySQL 服务器
-P 参数不加,默认连接的端口号是 3306
上述指令,可以有两种形式:
- 密码直接在
-p参数之后直接指定 (这种方式不安全,密码直接以明文形式出现在命令行) - 密码在
-p回车之后,在命令行中输入密码,然后回车
1.2 SQL 简介
SQL:结构化查询语言。一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
1.2.1 SQL 通用语法
1、SQL 语句可以单行或多行书写,以分号结尾。

2、SQL 语句可以使用空格/缩进来增强语句的可读性。

3、MySQL 数据库的 SQL 语句不区分大小写。

4、注释:
- 单行注释:
--注释内容或#注释内容 (MySQL特有) - 多行注释:
/* 注释内容 */
1.2.2 分类
SQL 语句根据其功能被分为四大类:DDL、DML、DQL、DCL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
2. 数据库设计-DDL
针对于数据库设计,主要包括三个阶段:
- 数据库设计阶段
- 参照页面原型以及需求文档设计数据库表结构
- 数据库操作阶段
- 根据业务功能的实现,编写SQL语句对数据表中的数据进行增删改查操作
- 数据库优化阶段
- 通过数据库的优化来提高数据库的访问性能。优化手段:索引、SQL优化、分库分表等
2.1 数据库操作
DDL 英文全称是 Data Definition Language (数据定义语言),用来定义数据库对象(数据库、表)。
DDL 中数据库的常见操作:查询、创建、使用、删除。
2.1.1 查询数据库
查询所有数据库:
show databases;查询当前数据库:
select database();用法
我们要操作某一个数据库,必须要切换到对应的数据库中。
通过指令 select database(),就可以查询到当前所处的数据库
2.1.2 创建数据库
语法:
create database [ if not exists ] 数据库名;注意:在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错。
- 可以使用
if not exists来避免这个问题
-- 数据库不存在,则创建该数据库;如果存在则不创建
create database if not extists my_database;2.1.3 使用数据库
语法:
use 数据库名 ;切换数据库
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则不能操作。

2.1.4 删除数据库
语法:
drop database [ if exists ] 数据库名 ;如果删除一个不存在的数据库,将会报错。
可以加上参数
if exists,如果数据库存在,再执行删除,否则不执行删除。
案例:删除 itcast 数据库
drop database if exists itcast; -- itcast数据库存在时删除命令执行效果如下:

说明
上述语法中的 database,也可以替换成 schema
- 如:
create schema db01; - 如:
show schemas;
2.2 表操作
关于表结构的操作也是包含四个部分:创建表、查询表、修改表、删除表。
2.2.1 创建
2.2.1.1 语法
create table 表名(
字段1 字段1类型 [约束] [comment 字段1注释 ],
字段2 字段2类型 [约束] [comment 字段2注释 ],
......
字段n 字段n类型 [约束] [comment 字段n注释 ]
) [ comment 表注释 ] ;注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号
2.2.1.2 约束
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。
作用:就是来保证数据库当中数据的正确性、有效性和完整性。
在MySQL数据库当中,提供了以下5种约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
MySQL数据库为解决id问题,提供了一个关键字:auto_increment(自动增长)
主键自增:auto_increment
- 每次插入新的行记录时,数据库自动生成 id 字段(主键)下的值
- 具有
auto_increment的数据列是一个正数序列开始增长(从 1 开始自增)
2.2.1.3 数据类型
MySQL中的数据类型主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-263,263-1) | (0,2^64-1) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char 与 varchar 都可以描述字符串,char 是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。
而 varchar 是变长字符串,指定的长度为最大占用长度 。相对来说,char 的性能会更高些。
示例:
用户名 username ---长度不定, 最长不会超过50
username varchar(50)
手机号 phone ---固定长度为11
phone char(11)日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
2.2.2 查询
查询当前数据库所有表
show tables;查看指定表结构
desc 表名 ; #可以查看指定表的字段、字段的类型、是否可以为NULL、是否存在默认值等信息查询指定表的建表语句
show create table 表名 ;2.2.3 修改
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];案例: 为 tb_emp 表添加字段 qq,字段类型为 varchar(11)
alter table tb_emp add qq varchar(11) comment 'QQ号码';修改数据类型
alter table 表名 modify 字段名 新数据类型(长度);alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];案例:修改 qq 字段名为 qq_num,字段类型 varchar(13)
alter table tb_emp change qq qq_num varchar(13) comment 'QQ号码';删除字段
alter table 表名 drop 字段名;修改表名
rename table 表名 to 新表名;2.2.4 删除
删除表语法:
drop table [ if exists ] 表名;
if exists:只有表名存在时才会删除该表,表名不存在,则不执行删除操作(如果不加该参数项,删除一张不存在的表,执行将会报错)。
3. 数据库操作-DML
DML英文全称是 Data Manipulation Language (数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
3.1 增加 (insert)
insert 语法:
向指定字段添加数据
insert into 表名 (字段名1, 字段名2) values (值1, 值2);全部字段添加数据
insert into 表名 values (值1, 值2, ...);批量添加数据(指定字段)
insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);批量添加数据(全部字段)
insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);
Insert 操作的注意事项:
插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
字符串和日期型数据应该包含在引号中。
插入的数据大小,应该在字段的规定范围内。
3.2 修改 (update)
update 语法:
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;案例:将 tb_emp 表中 id 为 1 的员工,姓名 name 字段更新为'张三'
update tb_emp set name='张三',update_time=now() where id=1;注意事项
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
在修改数据时,一般需要同时修改公共字段
update_time,将其修改为当前操作时间。
3.3 删除 (delete)
delete 语法:
delete from 表名 [where 条件] ;注意事项
DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
DELETE 语句不能删除某一个字段的值(可以使用
UPDATE,将该字段值置为NULL即可)。当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击
Execute即可。
4. 数据库操作-DQL
4.1 语法
DQL 查询语句,语法结构如下:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数查询分为以下几种类型:
- 基本查询(不带任何条件)
- 条件查询(where)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
4.2 基本查询
在基本查询的 DQL 语句中,不带任何的查询条件,语法如下:
查询多个字段
select 字段1, 字段2, 字段3 from 表名;查询所有字段(通配符)
select * from 表名;设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;去除重复记录
select distinct 字段列表 from 表名;
4.3 条件查询
语法:
select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between ... and ... | 在某个范围之内(含最小、最大值) |
| in(...) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 || | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
4.4 聚合函数
使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
select 聚合函数(字段列表) from 表名 ;注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
说明
count :按照列去统计有多少行数据。
- 在根据指定的列统计的时候,如果这一列中有
null的行,该行不会被统计在其中。
sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
max :计算指定列的最大值
min :计算指定列的最小值
avg :计算指定列的平均值
4.5 分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];注意事项
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
执行顺序:
where> 聚合函数 >having
where 与 having 区别(面试题)
- 执行时机不同:
where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。 - 判断条件不同:
where不能对聚合函数进行判断,而having可以。
4.6 排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;排序方式:
ASC :升序(默认值)
DESC:降序
注意事项:如果是升序, 可以不指定排序方式ASC
4.7 分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;注意事项
- 起始索引从 0 开始。
- 计算公式:
起始索引 = (查询页码 - 1)* 每页显示记录数 - 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL 中是
LIMIT - 如果查询的是第一页数据,起始索引可以省略,直接简写为
limit 条数
前端查询数据库的流程:
- 前端在请求服务端时,传递的参数
- 当前页码 page
- 每页显示条数 pageSize
- 后端需要响应什么数据给前端
- 所查询到的数据列表(存储到 List 集合中)
- 总记录数
示例
后台给前端返回的数据包含:List 集合(数据列表)、total(总记录数)
当数据量较大时,通常封装到 PageBean 对象中,并将该对象转换为 json 格式的数据响应回给浏览器。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageBean {
private Long total; // 总记录数
private List rows; // 当前页数据列表
}5. 多表设计
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
5.1 一对多 - 外键约束
一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
语法:
-- 创建表时指定
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);
-- 建完表后,添加外键
alter table 表名
add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);物理外键和逻辑外键
物理外键
- 概念:使用
foreign key定义外键关联另外一张表。 - 缺点:
- 影响增、删、改的效率(需要检查外键关系)。
- 仅用于单节点数据库,不适用与分布式、集群场景。
- 容易引发数据库的死锁问题,消耗性能。
- 概念:使用
逻辑外键
- 概念:在业务层逻辑中,解决外键关联。
- 通过逻辑外键,就可以很方便的解决上述问题。
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键
foreign key
5.2 一对一
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景:用户表(基本信息+身份信息)

- 基本信息:用户的ID、姓名、性别、手机号、学历
- 身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间)
如果在业务系统当中,对用户的基本信息查询频率特别的高,但是对于用户的身份信息查询频率很低,此时出于提高查询效率的考虑,可以将这张大表拆分成两张小表,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。他们两者之间一对一的关系,一个用户只能对应一个身份证,而一个身份证也只能关联一个用户。
那么在数据库层面怎么去体现上述两者之间是一对一的关系呢?
其实一对一我们可以看成一种特殊的一对多。一对多我们是怎么设计表关系的?是不是在多的一方添加外键。同样我们也可以通过外键来体现一对一之间的关系,我们只需要在任意一方来添加一个外键就可以了。

一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的 (
UNIQUE)
5.3 多对多
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
案例:学生与课程的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

6. 多表查询
6.1 概述
6.1.1 介绍
多表查询:查询时从多张表中获取所需数据
多表查询
单表查询的 SQL 语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如:select 字段列表 from 表1, 表2;
查询用户表和部门表中的数据:
select * from tb_emp , tb_dept;笛卡尔积:笛卡尔乘积是指在数学中,两个集合( 集合和 集合)的所有组合情况。
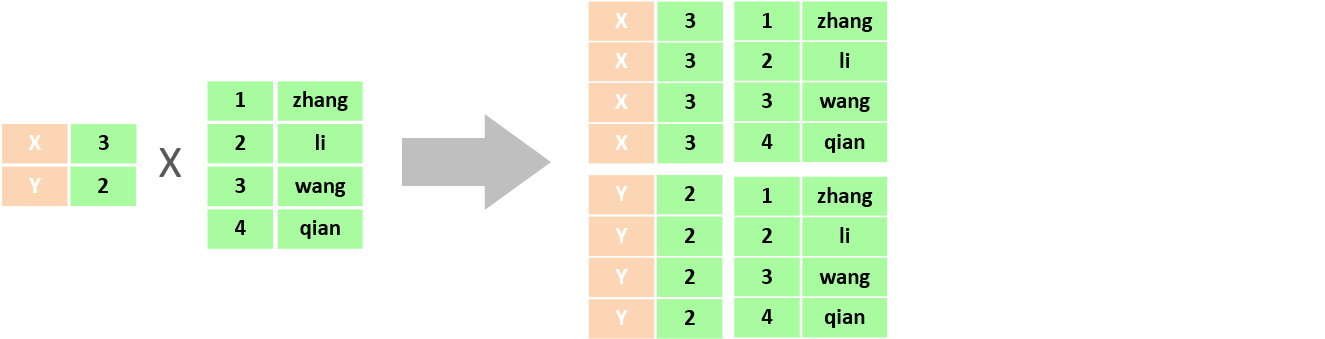
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据。
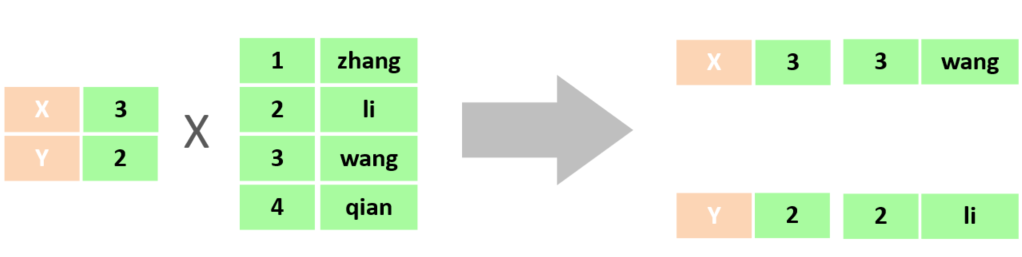
在查询时给多表查询加上连接查询的条件:
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;6.1.2 分类
多表查询可以分为:
连接查询
- 内连接:相当于查询 、 交集部分数据
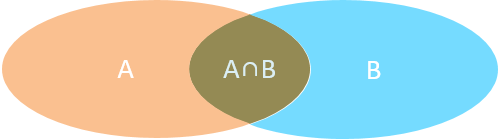
外连接
左外连接:查询左表所有数据(包括两张表交集部分数据)
右外连接:查询右表所有数据(包括两张表交集部分数据)
子查询
6.3 内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:
隐式内连接
显式内连接
隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;显式内连接语法:
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;多表查询时给表起别名:
- tableA as 别名1, tableB as 别名2 ;
- tableA 别名1, tableB 别名2 ;注意事项
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
6.3 外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;左外连接相当于查询表(左表)的所有数据,当然也包含表和表交集部分的数据。
右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;右外连接相当于查询表(右表)的所有数据,当然也包含表和表交集部分的数据。
注意事项
左外连接和右外连接是可以相互替换的,只需要调整连接查询时 SQL 语句中表的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
6.4 子查询
6.4.1 介绍
SQL 语句中嵌套 select 语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );子查询外部的语句可以是
insert / update / delete / select的任何一个,最常见的是select.
根据子查询结果的不同分为:
标量子查询(子查询结果为单个值「一行一列」)
列子查询(子查询结果为一列,但可以是多行)
行子查询(子查询结果为一行,但可以是多列)
表子查询(子查询结果为多行多列「相当于子查询结果是一张表」)
子查询可以书写的位置:
where之后from之后select之后
6.4.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: = <> > >= < <=
6.4.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
6.4.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
6.4.5 表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
7. 事务
7.1 介绍
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条 SQL 语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的 SQL 语句全部执行成功。如果其中有一条 SQL 语句失败,就进行事务的回滚,所有的 SQL 语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
7.2 操作
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条 sql 语句提交一次事务。(默认 MySQL 的事务是自动提交)
- 手动提交事务:先开启,再提交
事务操作有关的 SQL 语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
- 第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
- 第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
7.3 四大特性
原子性(Atomicity) :原子性是指事务包装的一组 sql 是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
- 一个事务的成功或者失败对于其他的事务是没有影响。
持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
关键
面试题:事务有哪些特性?
- 原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
8. 索引
8.1 介绍
索引 index :是帮助数据库高效获取数据的数据结构 。
- 简单来讲,就是使用索引可以提高查询的效率。
优点:
- 提高数据查询的效率,降低数据库的 IO 成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低 CPU 消耗。
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了
insert、update、delete的效率。
8.2 结构
MySQL 数据库支持的索引结构有很多,如:Hash 索引、B+Tree 索引、Full-Text 索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
二叉查找树
二叉查找树:左边的子节点比父节点小,右边的子节点比父节点大
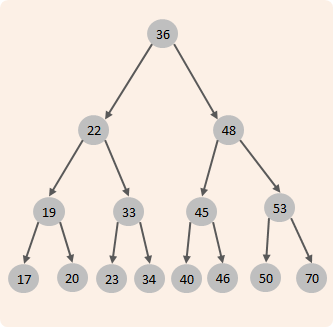
当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣。

可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)
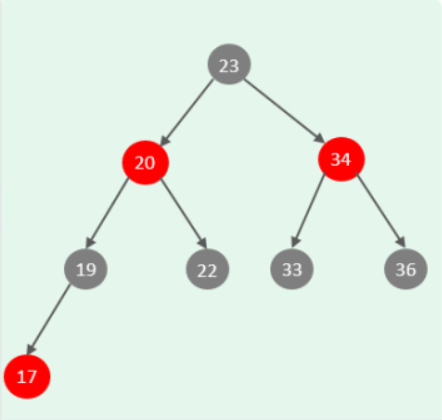
但是在 Mysql 数据库中并没有使用二叉搜索数或二叉平衡数或红黑树来作为索引的结构。
思考:采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
答案
最大的问题就是在数据量大的情况下,树的层级比较深,会影响检索速度。 因为不管是二叉搜索数还是红黑数,一个节点下面只能有两个子节点。此时在数据量大的情况下,就会造成数的高度比较高,树的高度一旦高了,检索速度就会降低。说明
如果数据结构是红黑树,那么查询 万条数据,根据计算树的高度大概是 左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要 次磁盘 IO,那么 万用户,那么会造成效率极其低下。
所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。而 B+Tree 就满足这种要求。
B+Tree(多路平衡搜索树)结构中如何避免这个问题:
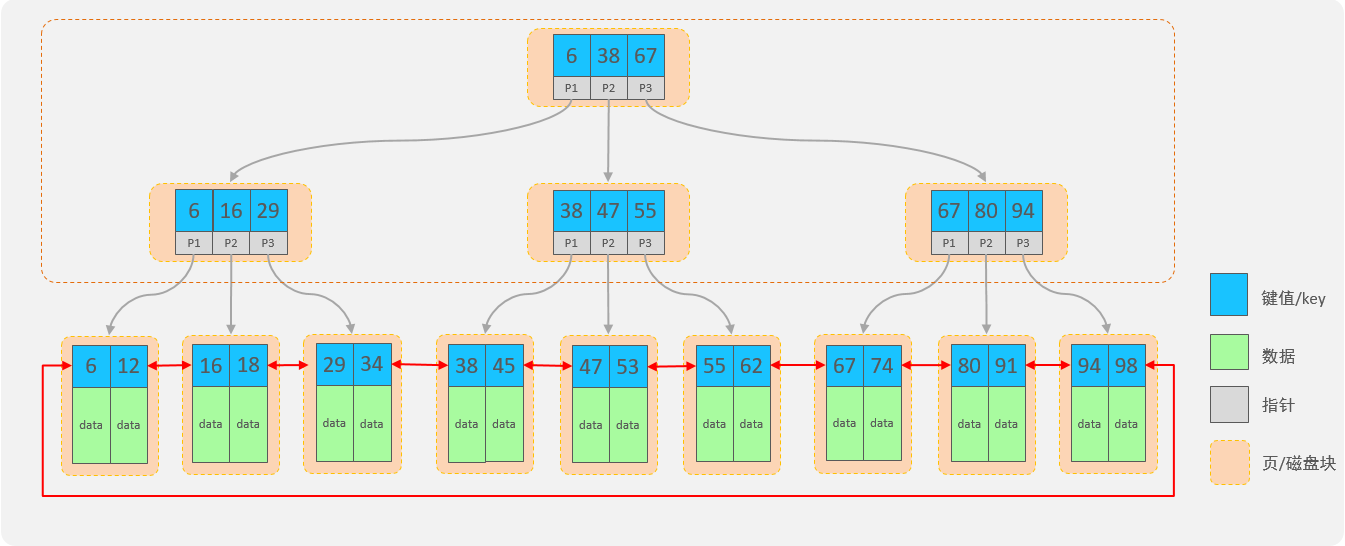
B+Tree 结构:
- 每一个节点,可以存储多个
key(有 个key,就有 个指针) - 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:
key + 指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
拓展
非叶子节点都是由 key + 指针域 组成的,一个 key 占 字节,一个指针占 字节,而一个节点总共容量是 ,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6) = 1170 个元素。
查看 mysql 索引节点大小:
show global status like 'innodb_page_size'; -- 节点大小:16384
当根节点中可以存储 个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储 个元素,那么第二层即第二次 IO 的时候就会找到数据大概是:。也就是说 B+Tree 数据结构中只需要经历两次磁盘 IO 就可以找到 条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由 key + 数据 组成,假设 key + 数据 总大小是 ,而每个节点一共能存储 ,所以一个第三层一个节点大概可以存储 个元素(即 条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是 个元素,那么第三层总元素大小就是: 结果就是 的元素个数。
结合上述分析 B+Tree 有如下优点:
- 千万条数据,
B+Tree可以控制在小于等于 的高度 - 所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
8.3 语法
创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;查看索引
show index from 表名;删除索引
drop index 索引名 on 表名;注意事项
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引