布隆过滤器在项目中的使用
布隆过滤器在项目中的使用
使用 布隆过滤器 快速判断某个元素是否在集合中出现了,可以用于解决 缓存穿透 的问题。
布隆过滤器提供一组 哈希函数 h1, h2, ..., hk,对需要存储的数据使用哈希函数计算得到 个哈希值,将 BitMap 中这 个位置都设置为 ,如果这 个位置都是 ,则 可能 在集合中,但是如果都不是 ,则 一定不在 集合中。
因此布隆过滤器会出现 误判 问题,可能将不在集合中的元素判断为在集合中,解决方法之一是可以通过 增加数组长度 来降低误判率。
缓存穿透: 请求的数据在数据库中不存在,因此数据也不会在缓存中,每次请求都不会命中缓存,而是打到数据库上,也就是直接穿过缓存打到数据库中,导致数据库压力很大甚至崩溃,这就是缓存穿透。
那么缓存穿透的话,可以使用 Redis 的 布隆过滤器 来解决:下载 RedisBloom 插件,该插件是 Redis 的布隆过滤器模块,下载之后在 Redis 的 conf 文件中配置之后即可使用
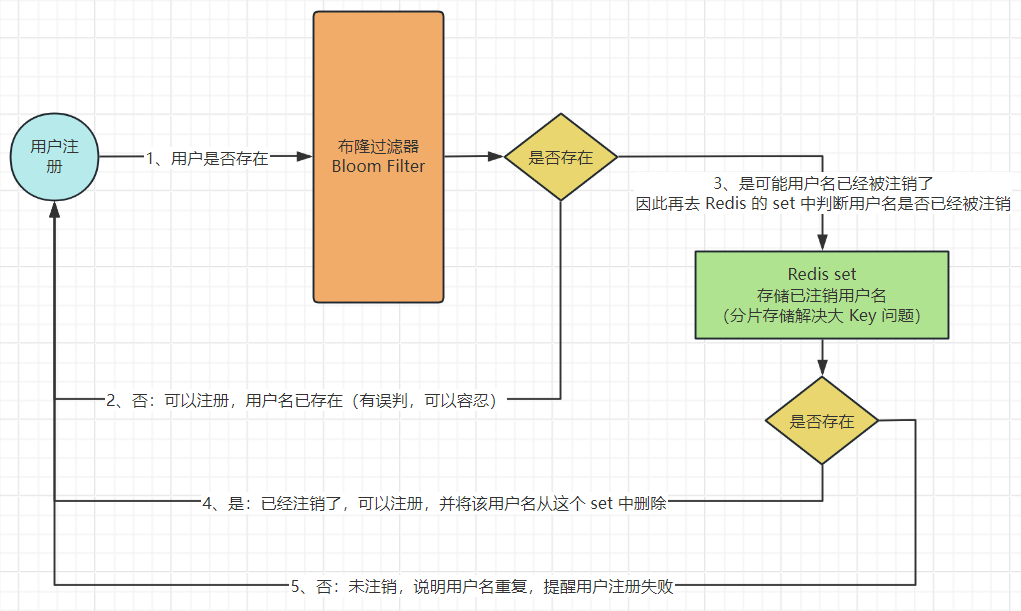
具体解决缓存穿透的场景,比如: 用户注册场景 ,如果系统用户量很大,在用户注册的时候,需要判断用户的用户名是否重复,初始将用户名的信息都初始化在布隆过滤器中,那么在用户注册时,先去布隆过滤器中快速进行判断用户名是否已经被使用,如果经过 次哈希计算发现这 次哈希值的位置上都为 ,说明 该用户名可能已经被使用了 ,用户注册用户名重复的话,大不了就换一个用户名就好了,这种情况是可以容忍的,之后用户注册成功之后,再将注册成功的用户名也放入的布隆过滤器中,这样在 用户注册时可以通过布隆过滤器快速判断用户名是否重复。
上边说了布隆过滤器可能存在 误判 的情况,误判是可以容忍的,但是布隆过滤器解决缓存穿透还存在另外一个缺点:无法删除元素。
无法删除元素 会导致如果用户注销帐号了,那么该用户名是无法从布隆过滤器中删除的,因此会导致其他用户也无法注册这个用户名,可以考虑再添加一层 Redis 缓存 来存储已经注销的用户名,同时如果注销的用户名较多的话,可能存在 大 key 问题 ,可以考虑分片存储来解决。
这里总结一下如何通过 布隆过滤器解决缓存穿透:
首先将用户名都初始化在布隆过滤器中,用户注册的时候通过 布隆过滤器 快速判断该用户名是否已经被使用了,系统可以容忍一定的误判率,对于布隆过滤器无法删除元素这个缺点,添加一层 Redis 缓存,将已经注销的用户名放在这个 Redis 中的 set 里,这样就可以解决布隆过滤器无法删除元素的缺点了,不过如果注销用户名多了,可能会存在大 key 问题,因此要考虑 分片存储 解决大 key 问题,也可以从业务角度上,限制每个用户注销的次数。
最后再说一下布隆过滤器中容量的计算:
先说一下各个参数的含义:
- m: 布隆过滤器中二进制
bit数组的长度 - n: 需要对多少个元素进行存储,比如说我们要存储 万个用户名,那么 万
- p: 期望的误判率,可以设置 或者
将 、 带入上述公式即可计算出来理想情况下布隆过滤器的二进制数组的长度,也可以根据此公式算出来存储这么多元素大概需要占用多少内存空间,比如需要存储 亿个用户名,期望误判率为 ,也就是将 亿、 带入,得到 约为 ,因此这个布隆过滤器大约占用 的空间(可以搜索在线布隆过滤器容量计算)