评论系统和可用性设计
评论系统和可用性设计
转载自stormspirit,原文链接:评论系统和可用性设计
存储设计
数据表设计
先看一张 b 站的评论图:
如上图所示,主评论下面有子评论,子评论之间也可以互相评论,并且评论之间是通过赞数进行排序的。
数据表设计:

如上图,评论系统分为三张表。
comment_subject
评论主题表。一个主题可能是一个视频稿件、一篇文章等。分成了 50 张表。自增 id 做主键。
obj_id 是主题 id, obj_type 是主题类型。
另外还保存了一些计数字段,比如评论总数等。这样做是为了避免每次需要统计总数时都要做一次 select count(*) ,这样效率很低,所以直接每次新增评论的时候就把相应字段 +1 即可。
comment_index
评论索引表。主要存的是评论的 id 与评论主题的对应关系,以及该评论的一些相关信息,比如是不是根评论、评论楼层,评论总数等。分成了 200 张表。使用自增 id 做主键,主键 id 就是评论 id。
root 是该评论的根评论 id,比如上面评论图红框里的就是根评论。不为 0 就是回复的评论,为 0 就是根评论。
parent 是这个评论的父评论,也就是它是回复哪条评论的,如果为 0 那这个评论就是根评论。
其他的都是一些统计信息等等。
comment_content
评论内容表。主要存的是评论实际内容。分成了 200 张表。
它直接使用 comment_id(对应的就是 comment_index 表的 id )作为主键,这样的好处是:
表都有主键,即 cluster index,是物理组织形式存放的,comment_content 没有 id,是为了减少一次二级索引查找,直接基于主键检索,同时 comment_id 在写入要尽可能的顺序自增。
意思是从 comment_index 表里捞出来一堆
comment_id,那就可以直接通过这些comment_id作为主键去查询 comment_content 表了。如果 content 表还有自己的自增主键的话,那么通过comment_id去查必然需要先查到自己的主键 id ,然后再通过 id 去查到这一行数据,多了一步操作。索引、内容分离,方便 mysql datapage 缓存更多的 row,如果和 content 耦合,会导致更大的 IO。长远来看 content 信息可以直接使用 KV storage 存储。比如 Rocks DB 等。
这也是一种 「索引内容分离」 的设计思想。
写数据
事务更新 comment_subject,comment_index,comment_content 三张表,其中 content 属于非强制需要一致性考虑的。可以先写入 content,之后事务更新其他表。即便 content 先成功,后续失败仅仅存在一条 ghost 数据。
读数据
基于 obj_id + obj_type 在 comment_index 表找到根评论列表,比如:
select id from comment_index where obj_id = 'x' and obj_type = 'y' and root = 0 ORDER BY floor;对于二级的子楼层,由于一般只查询 3 层子楼层:
select id from comment_index where parent/root in (上面查询出来的 id) and floor <= 3 order by floor;之后根据 comment_index 的 id 字段捞出 comment_content 的评论内容。
因为产品形态上只存在 「二级列表」,因此只需要迭代查询两次即可。对于嵌套层次多的,产品上,可以通过二次点击支持。
这种迭代查询的方式也可以直接用图数据库来实现,可能更好,比如 DGraph、HugeGraph 类似的图存储思路。
总结
主题一张表,评论索引与评论内容分开两张表来存,表里有一些统计字段,避免每次都重新统计。内容表的主键直接使用评论 id,避免使用评论 id 查询还需要回表。评论内容可以使用 kv 数据库。写入时可以先写评论内容表,评论索引表和主题表用一个事务更新。
缓存设计
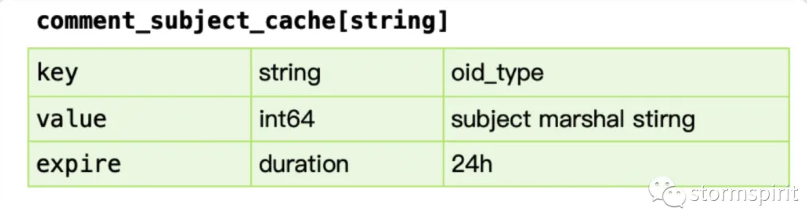

comment_subject_cache
对应主题的缓存,value 使用 protobuf 序列化的方式存入。
comment_index_cache
使用 redis sortedset 进行索引的缓存。key 是主题 id + 主题 type + 排序方式, member 就是评论 id,score 就是根据各种要素排序的得分。这样就可以根据某个主题查询,得到排序过后的评论 id 列表。然后就可以通过评论 id 列表去批量查询评论内容了。
提示
索引即数据的组织顺序,而非数据内容。参考过百度的贴吧,他们使用自己研发的拉链存储来组织索引,我认为 mysql 作为主力存储,利用 redis 来做加速完全足够,因为 cache miss 的构建,我们前面讲过使用 kafka 的消费者中处理,预加载少量数据,通过增量加载的方式逐渐预热填充缓存,而 redis sortedset skiplist 的实现,可以做到 O(logN) + O(M) 的时间复杂度,效率很高。
sorted set 是要增量追加的,因此必须判定 key 存在,才能 zdd。
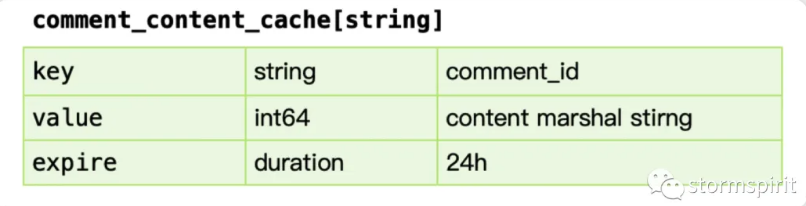
comment_content_cache
对应评论内容数据,使用 protobuf 序列化的方式存入。
缓存使用增量加载 + lazy 加载模式,也就是在查询第一页的时候会将后两页评论数据也一起加载进缓存。可以使用 kafka 进行缓存的异步构建。
可用性设计
缓存穿透
singleflight
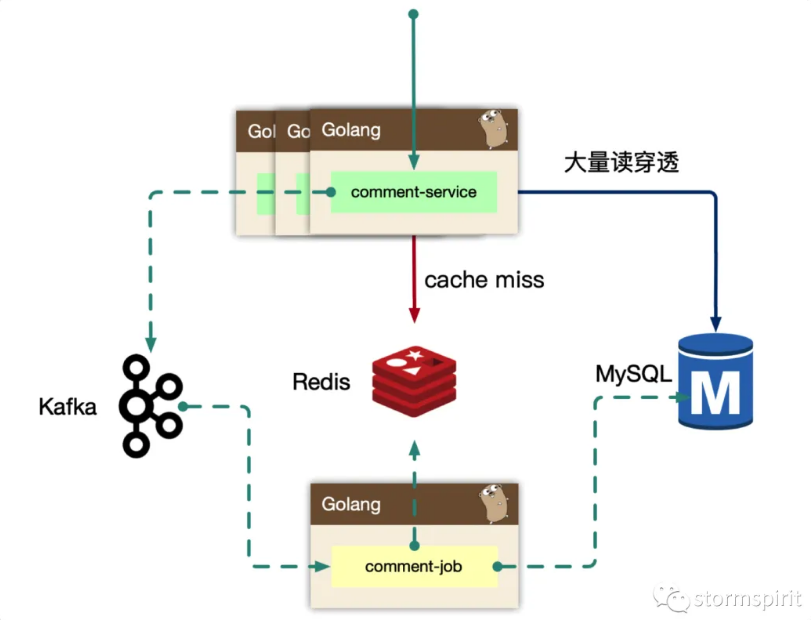
对于热门的主题,如果存在缓存穿透的情况,会导致大量的同进程、跨进程的数据回源到存储层,可能会引起存储过载的情况,如何只交给同进程内,一个人去做加载存储?
使用归并回源的思路 singleflight,singleflight 的原理可以看这篇文章 Go并发编程(十二) Singleflight。
同进程只交给一个人去获取 mysql 数据,然后批量返回。
同时这个租约 owner 投递一个 kafka 消息,做该 key 的 cache build 的操作。这样可以大大减少查询 mysql 的压力,以及大量透穿导致的密集写 kafka 的问题(如果不这么做那么会有很多的进程向 kafka 发送 cache rebuild 的指令,然后它们都会去 mysql 里查询数据写缓存)。
更进一步的,后续连续的请求,仍然可能会短时 cache miss,我们可以在进程内设置一个过期时间为 5 秒的 short-lived flag,标记最近有一个人投递了同一个 key 的 cache rebuild 的消息,如果有这个 flag ,那么相同的 kafka 消息直接 drop 而不会再去查 mysql 构建缓存,这样 mysql 的压力更小。
再进一步,可以在 comment-job 内存里设置一个过期时间很短的比如 5 秒的 LRU cache, 有一个线程去 mysql 里查到了数据就更新这个缓存,然后其他的线程直接从这个缓存里拿数据即可,这样就不用重复去 mysql 里查了,同样减少了对 mysql 的查询压力。
一般不需要使用分布式锁,实现起来太复杂而且很容易出错。
热点
流量热点是因为突然热门的主题,被高频次的访问,因为底层的 cache 设计,一般是按照主题 key 进行一致性 hash 来进行分片,但是热点 key 一定命中某一个节点,这时候 remote cache 可能会变为瓶颈,因此做 cache 的升级 local cache 是有必要的,我们一般使用**「单进程自适应发现热点」**的思路,附加一个短时的 ttl local cache,可以在进程内吞掉大量的读请求。
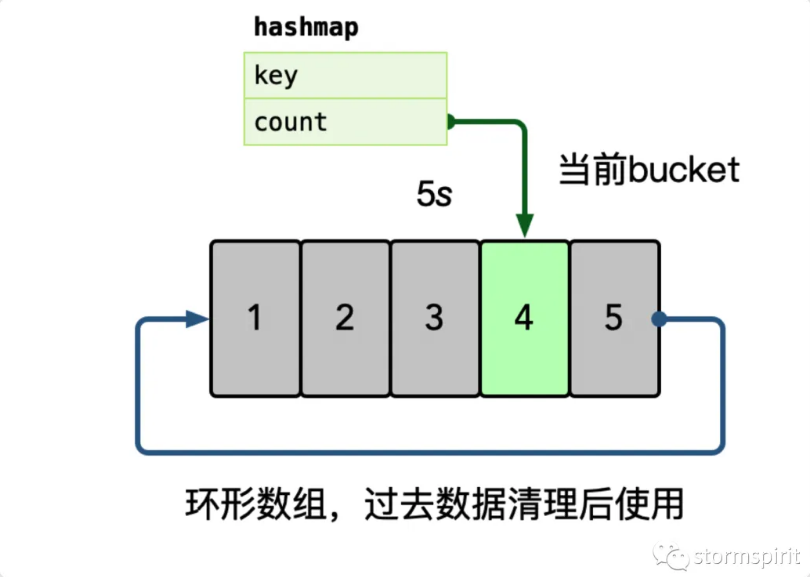
在内存中使用 hashmap 统计每个 key 的访问频次,这里可以使用滑动窗口统计(如下图),即每个窗口中,维护一个 hashmap,之后统计所有未过期的 bucket,汇总所有 key 的数据。
之后使用小顶堆计算 TopK 的数据,自动进行热点识别。把 TopK 的 key 统一 load 到本地缓存。